Day 4: NodeJS - FS Module

Developer based in India. Passionate learner and blogger. All blogs are basically Notes of Tech Learning Journey.
Need to work with files in NodeJS? Then "FS Module" is the solution you are looking for. FS Module stands for File System Module which helps us work with Files and also we can perform File Operations. We use this core module whenever we are in need to perform any file operation. File Operations are especially required when Backend Development comes into the frame.
As FS Module is a core module, we just need to import it in order to use its functionalities.
const fs = require("fs")
By writing the above statement, we will be able to perform a wide range of File Operations ranging from creating a file, writing some changes into a file, and so on.
Let's try to read the contents of the file. For this, we need to create a sample text file. You may create with any name and any content inside it. For example, this is the content of my text file.
Welcome to Node.
This is data1.txt file.

As you can the numbers on the console, yes this is the data from the file. Data is returned in ASCII format here. But it is not a readable format according to human readers. We need this data in Unicode Text Format so it is very much understandable. To do so, check this out.

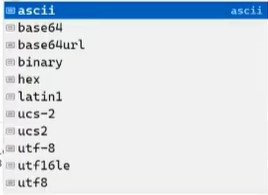
There are several other options too, other than UTF-8 here. By default the value is ASCII. For starters, these are the available options.
Now let us try to copy the data from one file to another. We will use the write method to do so.

I do not have the "copy_destination.txt" file created as of yet. Once the program is executed, the file will automatically be created with the data copied inside it. Thus on a basic level, we have completed read and write operations.
But sometimes there could be errors. We need to handle the errors for the smooth functioning of our program. As we are aware in programming languages, we use try-and-catch blocks to handle errors and exceptions, etc.
Let us try to handle one of the common errors i.e. "File Not Found". To demonstrate, I changed the file name in the code above from "data1.txt" to "data11.txt". We are well aware that at this point "data11.txt" does not exist.

As you can see the code for the File missing is "ENOENT". So let us try to handle it.

This above approach is a Synchronous approach. In the Synchronous approach, as we can see, we cannot proceed further until and unless a file has data in it. The operations of reading and writing will happen one after another. So there is a risk of a long waiting time.
Have a look at the Synchronous Approach.
const fs = require('fs')
// Reading the file and printing on console (SYNCHRONOUSLY)
console.log("##### Welcome #####")
try{
let contents = fs.readFileSync("data1.txt", "utf8");
console.log(contents)
// Copying the contents into another file
fs.writeFileSync("copy_destination.txt", contents) // where to copy, what to copy
console.log("Data Copied Sucessfully")
}
catch(err){
if(err.code === "ENOENT"){
console.log("The requested file cannot be found")
}
else{
throw err;
}
}
console.log("##### Goodbye #####")
##### Welcome #####
Welcome to Node.
This is data1.txt file.
Data Copied Sucessfully
##### Goodbye #####
Noticed anything? In the Synchronous Approach, the steps are performed one after another. Until step 1 is not completed, we will not head to next step. The tasks are performed sequentially. This may slow down the time of execution.
We can use the Asynchronous approach too. We will see that in the upcoming example.
// Reading the file and printing on console (ASYNCHRONOUSLY)
console.log(">>> Hello...")
fs.readFile("data1.txt","utf-8", (err,data) => { // Callback, there will be either error or data as an output
if(data !== undefined){ // if it is a data, then print on console and copy it to file
console.log(data)
fs.writeFile("file3.txt",data,(err)=>{ // pass the contents as in "data" variable
console.log("Data copied to file3.txt")
})
} else {
console.log( err)
}
})
console.log(">>> Bye...")
In an Asynchronous way, we give the callback. Unlike Synchronous, there is no need to handle exceptions or errors. Because we have specified in the callback function that it will automatically return the errors. The data gets copied successfully and in my case "file3.txt" gets created. Have a look at the console output and try comparing it with the console output in the Synchronous way we attempted earlier.
>>> Hello...
>>> Bye...
Welcome to Node.
This is data1.txt file.
Data copied to file3.txt
The main difference between the Synchronous approach and the Asynchronous approach is that in the Synchronous approach, we cannot proceed to task 2 until task 1 is 100 percent completed. Whereas in the Asynchronous Approach, while we are performing task 1, we will give a callback and proceed to the next step. In that way, we cannot block our thread.
To conclude,
We should always prefer to read using the Async, which means - readFile(...). A synchronous version of the same is readFileSync(...). Using async versions of a method make sure that we do not block our thread. This will help us perform tasks faster and in a more convenient way.




